文章 · 地震 AI
AI 為什麼老是漏看 S 波?
地震儀整天都在錄資料,台灣一年大概要記錄上萬次震動。從這些波形裡面挑出哪些是地震、發生在哪一刻, 傳統上是靠人去看波形圖,一個個標記。一個資深分析師可以標得很好,但量太大,分析師也是人,也要睡覺。
所以這幾年來,地震學家把這件事丟給深度學習。模型訓練完之後,丟一段波形進去, 它會告訴你哪個時刻有 P 波到達、哪個時刻有 S 波到達。
P 波跟 S 波是地震波的兩種類型。P 波跑得快,先到。S 波慢一點,後到,但破壞力更強, 房子搖晃感受最明顯的就是它。震源在哪、地震多嚴重,這兩個時間點都不能漏。
一個莫名其妙的失敗模式
問題是,AI 挑 P 波的時候表現得像個完美主義者,挑 S 波卻常常出包。 同一段波形,明明對人類來說 S 波的位置一目瞭然,模型偏偏給出一個歪掉、又長不大的小峰值, 剛好低於我們設定的偵測門檻,於是被當成沒看到。
更詭異的是,它看到的位置常常是準的。時間沒錯,就是高度不夠。
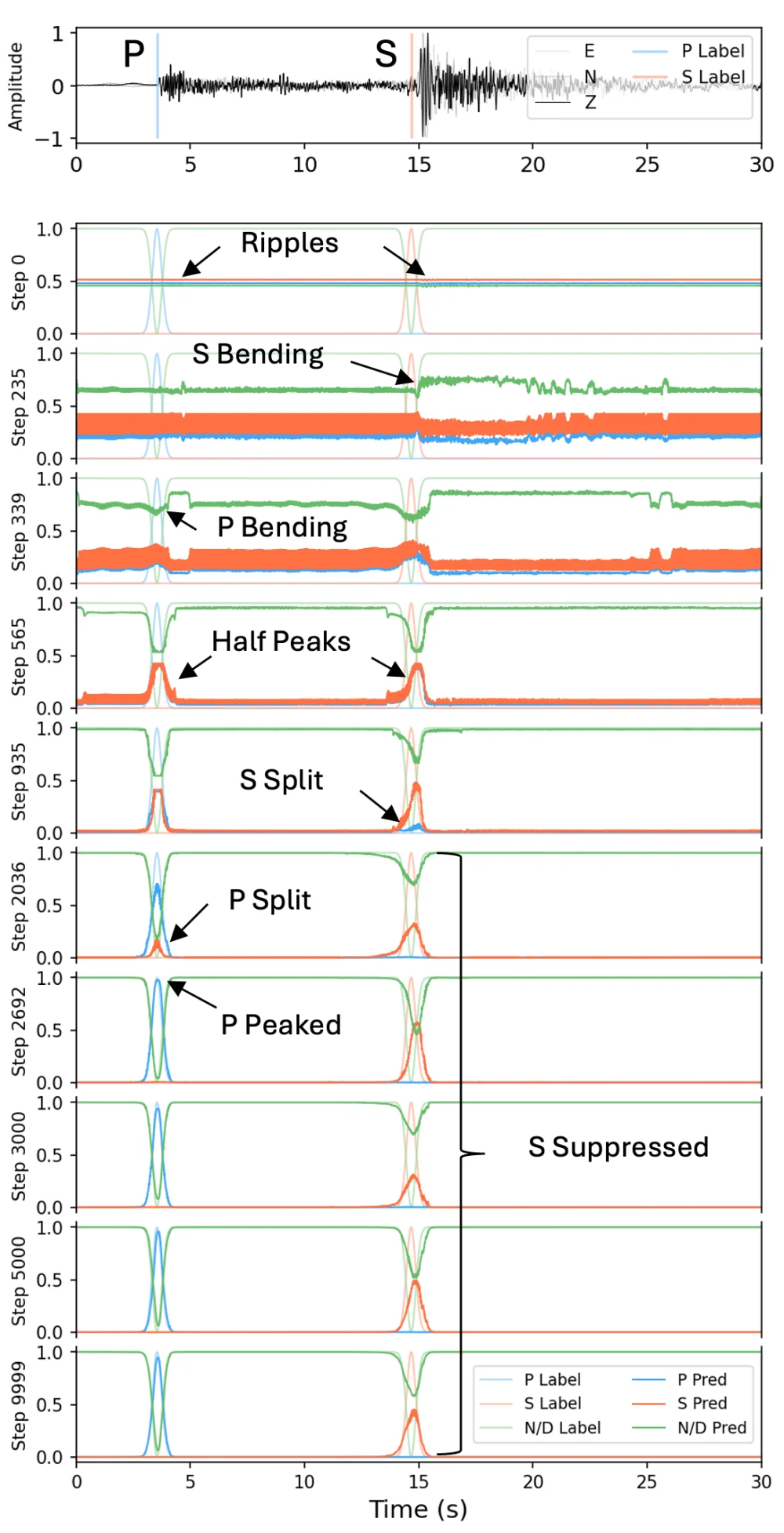
這個現象地震學界知道很多年了,大家通常的反應是換更大的模型、餵更多資料、調整訓練方法, 把它當成一個煩人的副作用慢慢繞過去。
這篇論文沒有想繞,作者想搞清楚到底為什麼。
為什麼會卡住
想像一下你要評一張肖像畫畫得像不像。直覺的做法是看整張臉。 但如果規則改成不准看整張,只能把畫面切成幾百個小格子,每格獨立打分,最後加起來,事情就麻煩了。
每一格只能告訴你這格該調亮還是調暗。沒有任何一格能告訴你整張臉的位置應該往左移一點。 所以當預測的形狀正確、位置卻往右偏了一點點,每一格收到的訊號都是你不夠亮、把自己壓低。 預測越畫越淡,但位置永遠不會被修正。
傳統訓練 AI 找 S 波的方式,正好就是這種逐格打分。它沒有任何機制告訴模型整體應該往哪邊挪, 只能上下調亮度。S 波預測就這樣卡在某個位置不上不下,把自己越壓越扁。
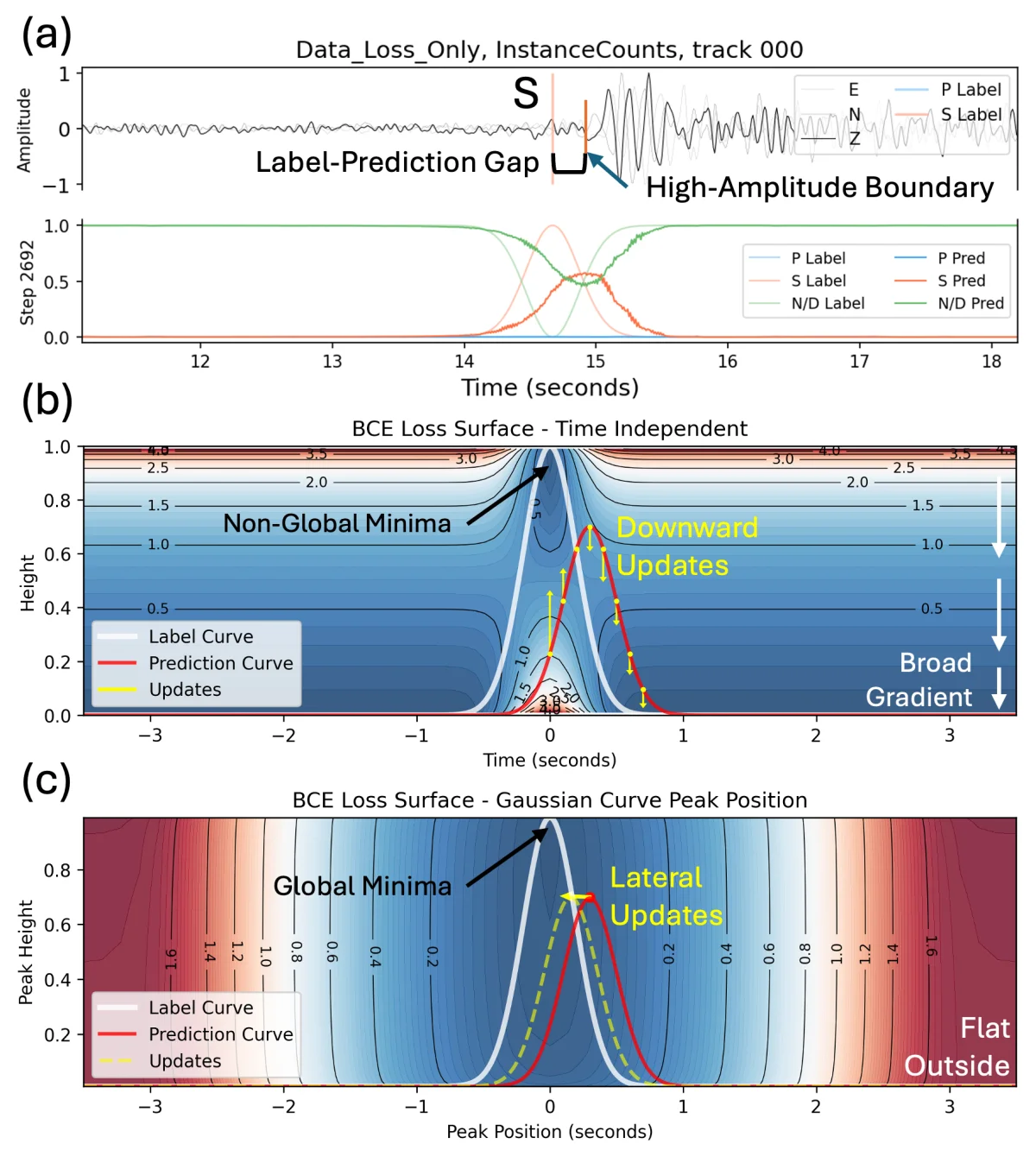
S 波特別容易中招,還因為兩件事火上加油。第一,它的標準答案本身就比較模糊: S 波傳得遠了之後波形會變胖、邊界變糊,連人類專家標出來的位置都會差個幾百毫秒,訓練資料裡正確答案就帶噪音。 第二,AI 模型天生愛尖銳的東西,會把預測錨在波形上最明顯的轉折,剛好不是 S 波該在的位置。
三件事湊在一起,把 S 波預測困死在一個無解的角落。
解法
診斷找到了,解法就好辦。
作者用了一個叫 GAN 的技術。GAN 通常用來生假照片或假影片,原理是讓兩個模型互相對抗, 一個負責生產,一個負責挑剔。生產的努力騙過挑剔的,挑剔的努力分辨真假, 最後生產的被逼得越來越像真貨。
在這篇論文裡,挑剔的那個鑑別器的工作是看一眼模型輸出,判斷整體形狀像不像真正的標籤。 它不在乎每一格獨立的數值,它看的是整張臉。
這就補上了原本缺失的那個訊號。模型不能只把每格的亮度調對,它必須讓整張臉說得過去, 否則鑑別器一眼就揪出來。
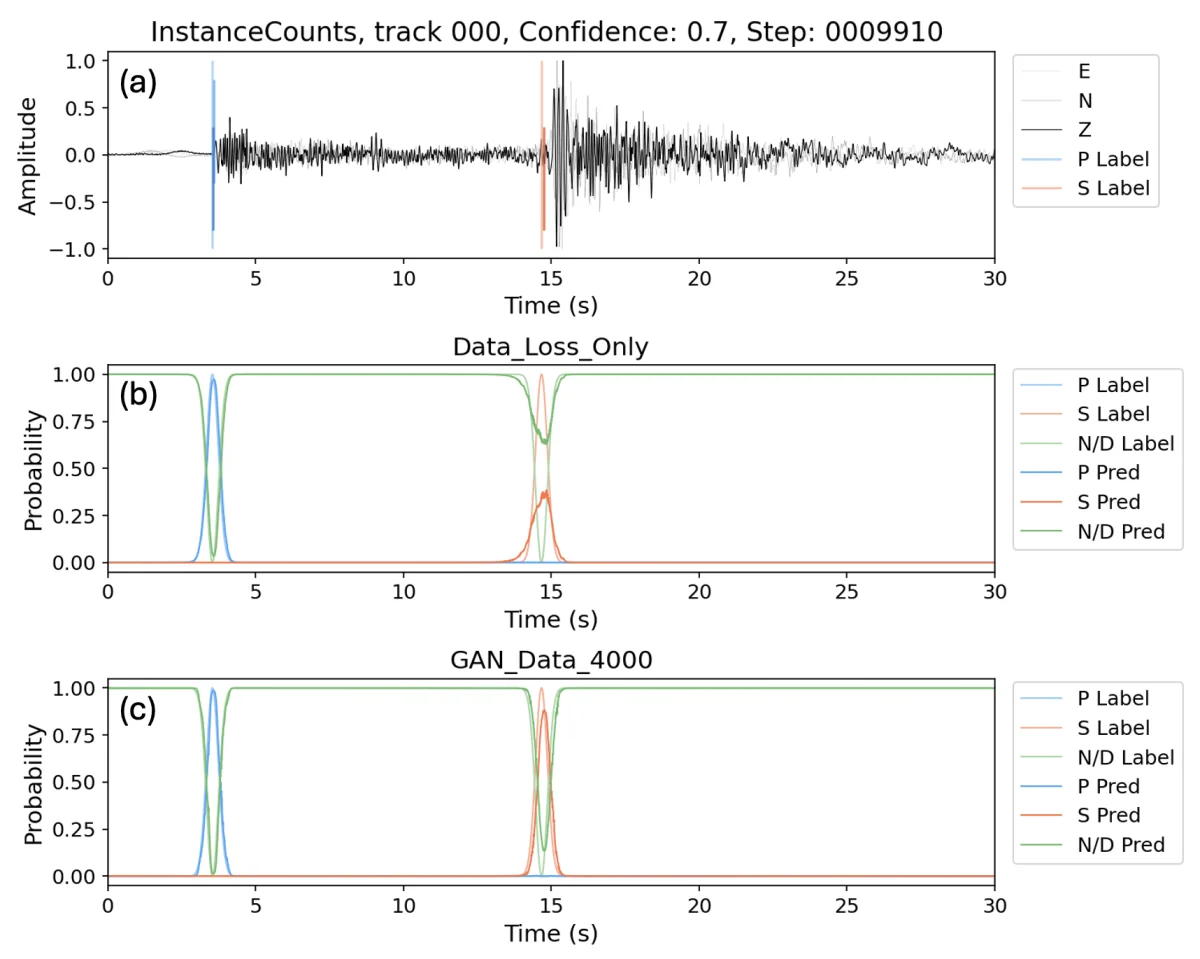
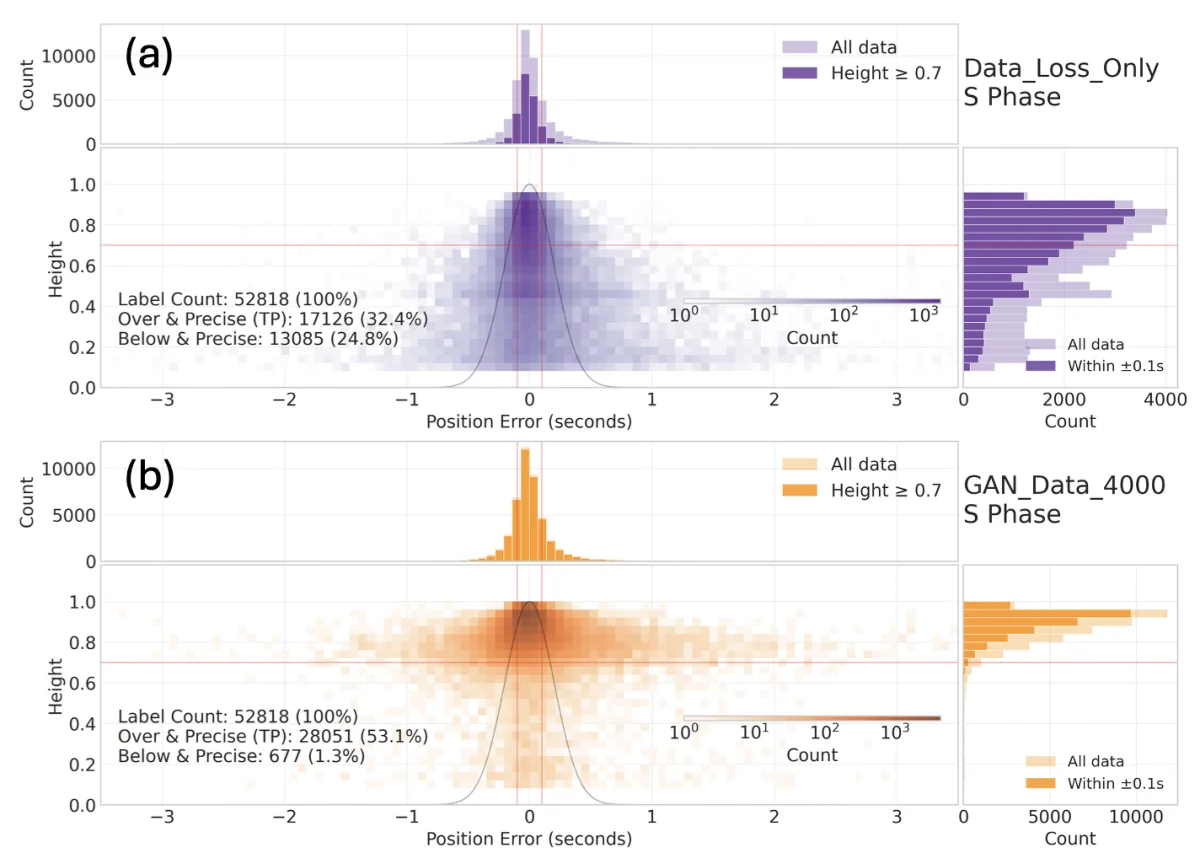
為什麼這件事比 64% 重要
64% 這個數字很漂亮,但這篇論文真正讓人覺得有趣的地方不是它。
它真正做到的事情,是把一個原本被當成工程麻煩的現象,拆解成一個可以被理解、被預測、被分析的東西。 為什麼會卡住、卡在哪、怎麼放出來,全部能講清楚。整個流程從試誤推到了原則性分析。
這套診斷不只能用在地震。任何需要從訊號裡標出時間點的任務都適用, 心電圖上的心跳、衛星訊號裡的事件、語音裡的音節邊界。 只要標準答案是一個有形狀的東西,傳統的逐點打分都可能讓你掉進同一個陷阱。
論文最後其實在提一個觀念:理解損失函數本身的形狀,重要程度不輸理解模型架構。 我們很習慣討論換哪種網路、加幾層、用哪個函數,但很少有人停下來問, 你叫模型優化的那個目標,它本身的形狀長得對不對。
評分標準錯了,再厲害的模型也是白搭。
參考文獻
Huang, C.-M., Chang, L.-H., Chang, I.-H., Lee, A.-S., & Kuo-Chen, H. (2025). Recovering Sub-threshold S-wave Arrivals in Deep Learning Phase Pickers via Shape-Aware Loss. arXiv preprint, arXiv:2511.06731.
arxiv.org/abs/2511.06731
ResearchGate
程式碼:github.com/SeisBlue/BlueDisc
附錄:訓練過程動畫
本文第一張圖的動畫版。隨著訓練步數推進,可以看到 S 波預測如何一路被壓到偵測門檻以下。